Independent. Human-Curated. Established 2007.
How to Build a Google Knowledge Graph Without Wikipedia
DirJournal Founder · 19+ years building directory and discovery products. Editorial-team verified.
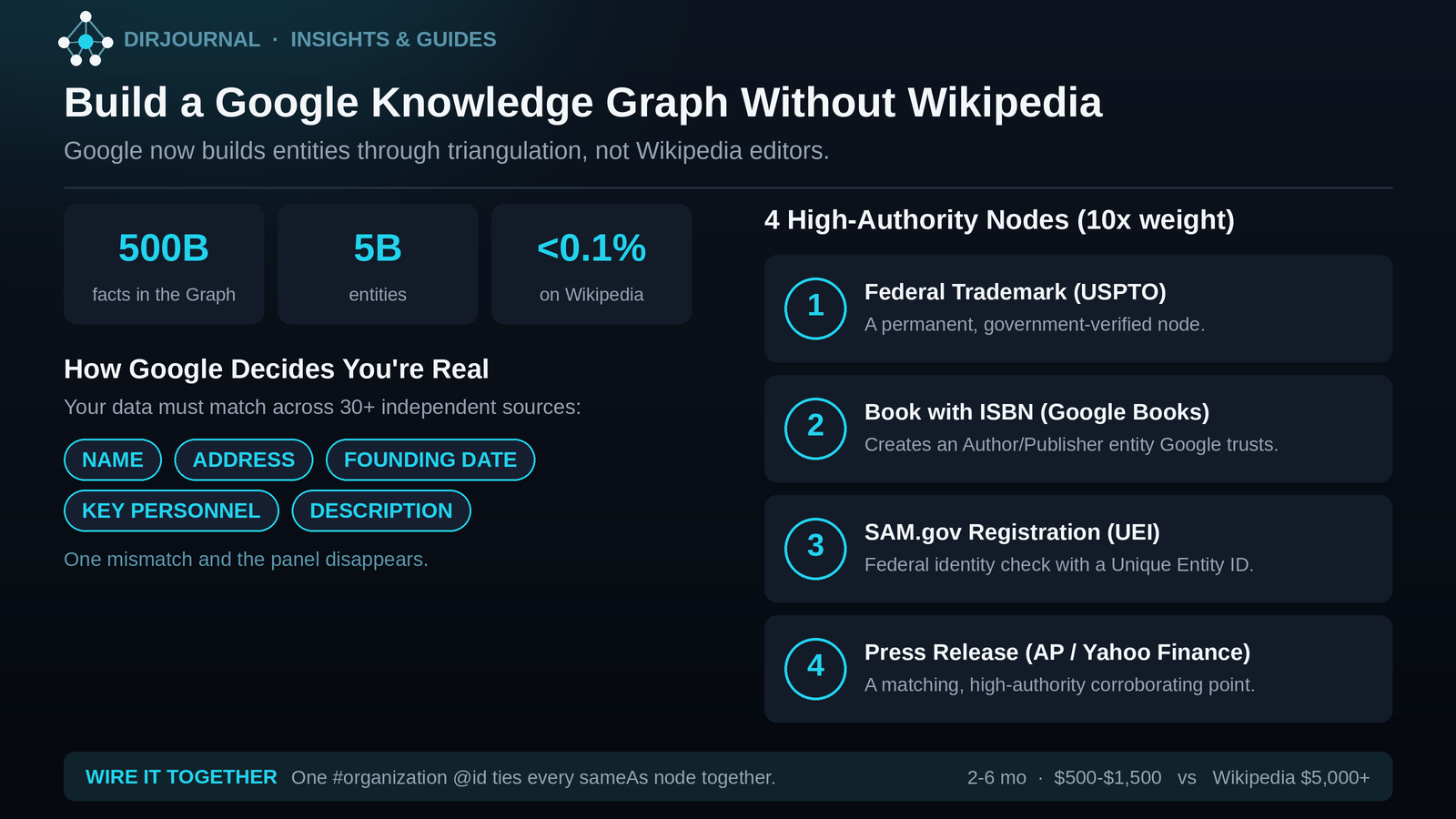
You do not need a Wikipedia page to get a Google Knowledge Panel. Google now builds entity recognition through triangulation — matching your business data across 30+ independent sources. This guide covers the technical, legal, and strategic methods to force your way into the Knowledge Graph using trademark filings, ISBNs, government databases, and structured data.
You Do Not Need Wikipedia to Exist in Google's Brain
For years, the conventional wisdom was clear: if you want a Google Knowledge Panel, you need a Wikipedia page. And if you're not famous enough for Wikipedia, tough luck — you're just a string of text in a database, not a "thing" that Google recognises as a distinct entity.
That's changed. Google's shift from "strings to things" is largely complete, and the Knowledge Graph now recognises businesses through a process that has nothing to do with Wikipedia editors. The algorithm looks for your data across dozens of independent sources, checks whether it all agrees, and — if it does — promotes you from anonymous text to a verified entity with a Knowledge Panel.
The businesses figuring this out are getting panels without any Wikipedia involvement at all. Here's how they're doing it.
How Google Decides You Are Real
Google doesn't trust your website. That's not an insult — it's just how the system works. Any website can claim anything. So the algorithm uses what amounts to triangulation: it looks for your business data to be mirrored across at least thirty independent, authoritative sources. When the name, address, founding date, key personnel, and description match across those sources, Google gains enough confidence to create an entity.
The practical implication is that consistency matters more than any single listing. Your About page, your LinkedIn company profile, your Crunchbase entry, your state business filing, your directory listings — they all need to say exactly the same thing. One mismatch and the confidence score drops.
Your Entity Home and Why It Matters
Before you do anything else, you need to designate one URL as the canonical source of truth for your business. This is usually your About page or your homepage. Two things make it work:
First, write it in factual language, not marketing copy. "Acme Corp is a B2B software company founded in 2019 by Jane Smith, headquartered in Austin, Texas" is what the Knowledge Graph can parse. "We're the world's most innovative solution for modern enterprises" is noise that the algorithm ignores.
Second, anchor it with a stable @id in your Schema markup. Use your homepage URL followed by a fragment — something like https://example.com/#organization. This acts as a digital fingerprint that connects every other mention of your brand back to this specific node. Every sameAs link you add to your JSON-LD should point outward from this anchor.
The Government and Legal Nodes That Carry Disproportionate Weight 4 Methods
When you register a trademark with the USPTO, you create an entry in a government database that Googlebot indexes. This isn't just brand protection — it's entity verification. Make sure the business name and address on the filing match your "entity home" exactly. A trademark filing is a permanent, legally verified node that no third-party service can revoke.
Google Books is one of the primary seed databases for the Knowledge Graph. Publishing even a short industry whitepaper as an ebook on Amazon and Google Play — with a proper ISBN — creates an "Author" or "Publisher" entity in a data source that Google treats as high-trust. This route is dramatically underused. The book doesn't need to be a bestseller; it just needs to exist with a valid ISBN.
Registering on the System for Award Management (the federal contractor database) requires rigorous identity verification. The resulting public record, complete with a Unique Entity ID (UEI), gives Google a government-verified data point that almost nothing else can match. You don't need to actually bid on government contracts — the registration itself creates the entity node.
The press release isn't about the backlink — it's about creating a matching data point on AP News or Yahoo Finance. Include your entity home URL and social profiles in the boilerplate. Google uses these high-authority news sources to verify that your business is active and that the data matches what it's seeing elsewhere.
Found this useful?
Share this article
Recommended for You

Are Links Dead? Our 2021 Verdict + What's Changed in 2026
Links aren't dead in 2026 — but they got demoted. For Google's traditional rankings, backlinks still

Best Legal Directories for Law Firms in 2026: Which Ones Actually Move the Needle
An independently scored guide to the 18 best legal directories — with domain authority, traffic figu

The Claude Connectors List, Organized by People Who Build Directories (2026)
Claude connectors are prebuilt, hosted integrations that link Claude to outside services like Gmail,
Deep Dive Resources
Related topics consolidated into this guide:
- The Best Business Directories for SEO in 2026
Related Resources
Looking for verified service providers? Browse our directory categories below — all human-audited and trusted by decision-makers since 2007.
The Comparison: Wikipedia Strategy vs. Triangulation Strategy
| Factor | Legacy "Wikipedia" Route | 2026 Triangulation Route |
|---|---|---|
| Primary driver | Wikipedia / Wikidata page | Multi-node data correlation |
| Risk of deletion | High — editors are aggressive | Low — you control the nodes |
| Success metric | Press coverage in major news | Data consistency across 30+ sources |
| AI visibility | High but easily hallucinated | Maximum — AI treats nodes as facts |
| Typical cost | $5,000+ for PR/Wiki experts | $500–$1,500 in technical labour + time |
| Time to panel | 3–12 months (if approved) | 2–6 months with consistent effort |
Connecting It All With Structured Data
The Schema markup that ties these nodes together isn't complicated, but it has to be precise. Your Organization JSON-LD should include sameAs links to every authoritative source where your business appears — your LinkedIn, your Crunchbase, your Google Books entry, your USPTO filing, your key directory listings.
The @id must be stable. The name must match across all nodes. The contactPoint data must be current. Every time you change something — a phone number, an address, a service description — it needs to be updated everywhere simultaneously, or the Knowledge Graph's confidence in your entity degrades.
LinkedIn Company Page — your primary professional identity
Crunchbase — especially for tech/startup businesses
Google Books — if you published with an ISBN
USPTO Trademark — your legal verification anchor
High-DA Directory Listings — human-verified authority nodes
State Business Filing — Secretary of State registration
SAM.gov — government contractor database entry
Checking Whether Google Has Accepted Your Entity
There are two reliable ways to know if you've crossed the threshold:
The Knowledge Graph Search API is a developer tool that lets you query Google's entity database directly. If it returns a kgmid (a Knowledge Graph machine ID) for your brand, you're officially a "thing" in Google's understanding. If it returns nothing, you're still a string.
Search Console's social channel association feature is the other signal. If Google shows that it has successfully connected your social profiles to your website, that's confirmation of entity recognition.
Maintenance is Not Optional
A Knowledge Panel isn't permanent. If your data becomes inconsistent — you change your phone number on LinkedIn but forget to update your trademark filing, or your directory listing shows an old address — Google's confidence score drops, and the panel can disappear.
Audit your top thirty citation sources quarterly. Make sure every one of them reflects your current, correct information. The entity web you've built is only as strong as its weakest node, and one outdated profile can undermine years of careful triangulation.
The goal isn't just to rank. The goal is to be verified — recognised by Google and the AI agents that increasingly sit between your business and your customers as a distinct, trustworthy entity. That recognition compounds over time, and it starts with getting the data right across every node where you exist.
Your Knowledge Graph Action Checklist
@id and sameAs links in your Organization JSON-LD schemakgmid